A mental model is a compression of how something works. Each model is a lens which you see the world through. Each lens offers a different perspective, revealing new information. Looking through one lens lets you see one thing, and looking through another lets you see something else. Looking through them both reveals more than each one individually.
Let’s take the example of how you should cram for exams.
-
Optimize for learning velocity. Velocity is a mental model that helps you understand that both speed and direction matter. A successful cram means learning the right things fast. If you’re learning the wrong things fast, you’re effeciently ineffective. If you’re going fast but in the wrong direction, you’ll just get to the wrong place faster.
-
Have tight feedback loops Feedback loops are a mental model that helps you understand that actionable feedback matters. Set up tight feedback loops to gauge that what you’re a) learning something relevant and b) you’re actually learning it. Having tight feedback loops allows you to quickly evaluate if you’re actually learning and retaining the right material, and enable real-time adjustments to your approach.
A quick start is charting a map of what content to cover. Split the course into your training set (lectures/practice problems), validation set (practice solutions), and test set (past/practice exams). Ask your friends for help. They’re probably cramming as well.
LLMs like ChatGPT and Claude are your best friends for cramming. They can act as tight feedback loops that help you speedrun course content by helping you:
- Practice quizzing yourself frequently to gauge your understanding of concepts
- Work through practice exams/problems to identify gaps in your knowledge
- Get feedback on what you’re confused about / which solutions you got wrong to get unstuck Without these feedback mechanisms, you may spend too much time forming incorrect intuitions, developing ineffective study habits, or missing core concepts altogether. The feedback loops align your learning velocity.
To grok (according to Oxford English Dictionary) is “to understand intuitively or by empathy, to establish rapport with” and “to empathize or communicate sympathetically (with); also, to experience enjoyment” Then Grokking is enjoying the process of learning the most relevant things in the fastest way possible.
- Have high margin of safety. Margin of safety is a mental model that helps understand that things don’t always go as planned. Cramming for exams is a canonical experience where values are conditioned by real-life tradeoffs. The stress of being pressed for time is the price paid for procrastinating - a fee, not a fine, because the tradeoff was made to buy time for other, hopefully more fulfilling, activities. Strategic procrastination is a leveraged investment, borrowing study time for expected higher returns elsewhere.
My favorite quote: “a high margin of safety renders forecasting unnecessary.” Procrastination is a protective mechanism for the ego. If you well on the exam, great! You’ve proven you can perform under pressure. If you didn’t do well or failed, well… it’s not skill issue. it’s will issue. You just didn’t care enough, or didn’t know it was that difficult. There are many reasons why, but the most socially plausible one works the best to protect your ego :) At least you’re self-aware now. It’s because you made a strategic tradeoff that happened to not play out in your favor. This cursed timeline was self-imposed, and you did your best. No biggie, just do better next time.

Procrastination is a timeless companion, faithfully tagging along through life’s journeys as an ever-available option. The cognitive dissonance from the important decisions serves as a prompt to procrastinate productively.
Stochastic gradient descent (SGD) is a mental model that helps us understand why productive procrastination leads to better decisions.
This explanation is lengthier than the previous three mental models, but trust me it’s worth it.
Here’s the technical definition of SGD from Wikipedia:
Stochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. differentiable or subdifferentiable). It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient (calculated from the entire data set) by an estimate thereof (calculated from a randomly selected subset of the data). Especially in high-dimensional optimization problems this reduces the very high computational burden, achieving faster iterations in exchange for a lower convergence rate.
I admit I barely understand this. Let’s try a simpler explanation, trading in accuracy for better functional understanding. SGD is literally f*ck around and find out (with a tight feedback loop).
You’re expected to train your decision-making model to predict the best decision for any new unseen input. (new challenges/problems) Your “training data” refers to the dataset (perspective) used to iteratively update the model’s parameters (assumptions) and minimize the prediction error (of not making the best decision).
SGD explanation
Specifically, the training data for Stochastic Gradient Descent (SGD) includes:
- Input data/features - These are the data points or examples the model uses for predictions. For instance, in image classification, the input data would be the images themselves.
- Ground truth labels - The accurate output values for the input data. In the case of image classification, these would be the correct labels for each image (e.g., cat, dog).
Real-life decisions, unlike training data, lack clear “ground truth labels,” making it challenging to identify the best choice amidst numerous hypotheticals and alternate outcomes. However, we often rely on intuition to make decisions we hope not to regret.
The objective or cost function that SGD optimizes aims to align the model’s predictions with these ground truth labels. It’s a measure of how well our intuition or gut feeling matches the actual outcomes upon reflection.
Each iteration of SGD applies a mental model to gain new insights into the problem by:
- Sampling a random batch of input data points and their corresponding labels from the training data.
- Making predictions on this batch with the current model parameters.
- Calculating the errors between these predictions and the true labels to compute the gradient of the cost function.
- Updating the parameters in the direction that reduces this error gradient.
Thus, the training data serves as “guide rails,” providing the supervisory signal for iterative learning and optimization by the model.
The ultimate goal is for the model’s predictions to closely match the ground truth labels upon SGD’s convergence, enabling the optimized model to generalize effectively to new, unseen data inputs.
The key points:
- You only “see” and utilize partial information from one point at a time (stochastic/random). Since you can’t process all the perspectives at once (limited by compute/attention)
- You take multiple descent steps, with each step informed by new local information
- Getting randomly relocated prevents you from endlessly descending down small local valleys
Ok, now we updated our priors with a silly intution on what it means for SGD to be literally f*ck around and find out (with a tight feedback loop). Here’s how it looks like:
Imagine you’re trying to find the lowest point in a hilly landscape, but you’re blindfolded and can only probe the ground around you. This landscape represents the high-dimensional error surface you’re trying to minimize when training a machine learning model.
Instead of calculating the slope (gradient) of the entire landscape at once, which is extremely difficult, SGD takes a different approach:
- You start at a random point on the landscape.
- You take off the blindfold, look around your local area, and estimate the direction for steepest descent just based on what you can see.
- You take a step in that direction of steepest descent.
- You put the blindfold back on, get picked up and dropped at a new random point on the landscape.
- Repeat steps 2-4 many times.
Any individual step is a rough approximate descent in the most promising direction. The randomness is the source of entropy that gives us the different perspective to make incremental updates. That entropy dislodges us from local minima. This allows us SGD to effectively explore and map out the entire landscape, without infinite data/compute to analyze everything globally upfront.
SGD is cycling through variants of mental models to converge on the best perspective to make the best decision. Productive procrastination is SGD, where you iteratively
- introduce new perspectives (f*ck around)
- update your priors
- and find out (what the best direction to f*ck around is)
SGD is f*ck around and find out with tight feedback loops for course-correction. It’s how you optimize the explore/exploit tradeoff. It’s how you speedrun the best perspective for the best decisions. Productively procrastinating with SGD is how you optimize for the explore/exploit tradeoff when faced with an important challenge with a deadline.
Procrastination is a feature, not a bug. It’s reasonable, and encouraged to procrastinate. But if you’re going to procrastinate, do it more productively with SGD.
In essence, productive procrastination is SGD: f*ck around and find out with tight feedback loops for course-correction. It’s cycling mental models to not get trapped in local maxima in the search for life’s global maxima. It’s iteratively exploring new perspectives and updating your priors just as SGD algorithms iteratively escape local minima through randomized updates towards the bottom.
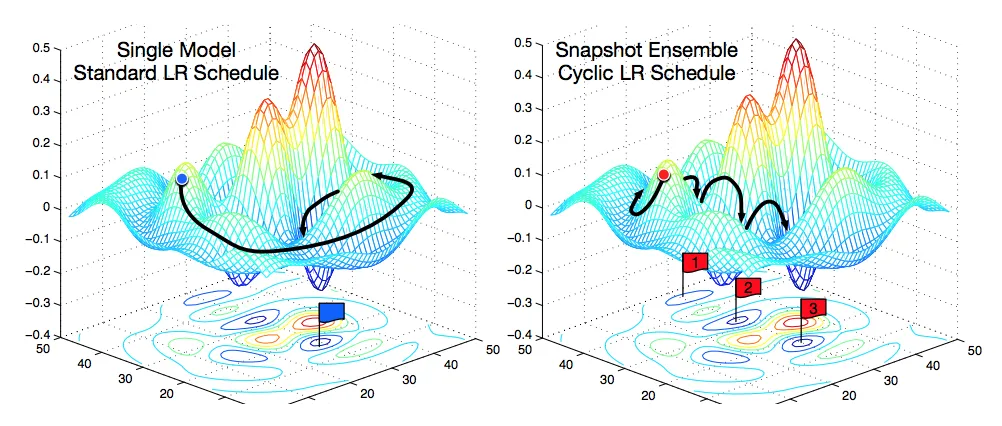 The model on the left slowly descends into a local minimum, while the model on the right jumps in and out of several local minimums, searching for a more stable one.
The model on the left slowly descends into a local minimum, while the model on the right jumps in and out of several local minimums, searching for a more stable one.