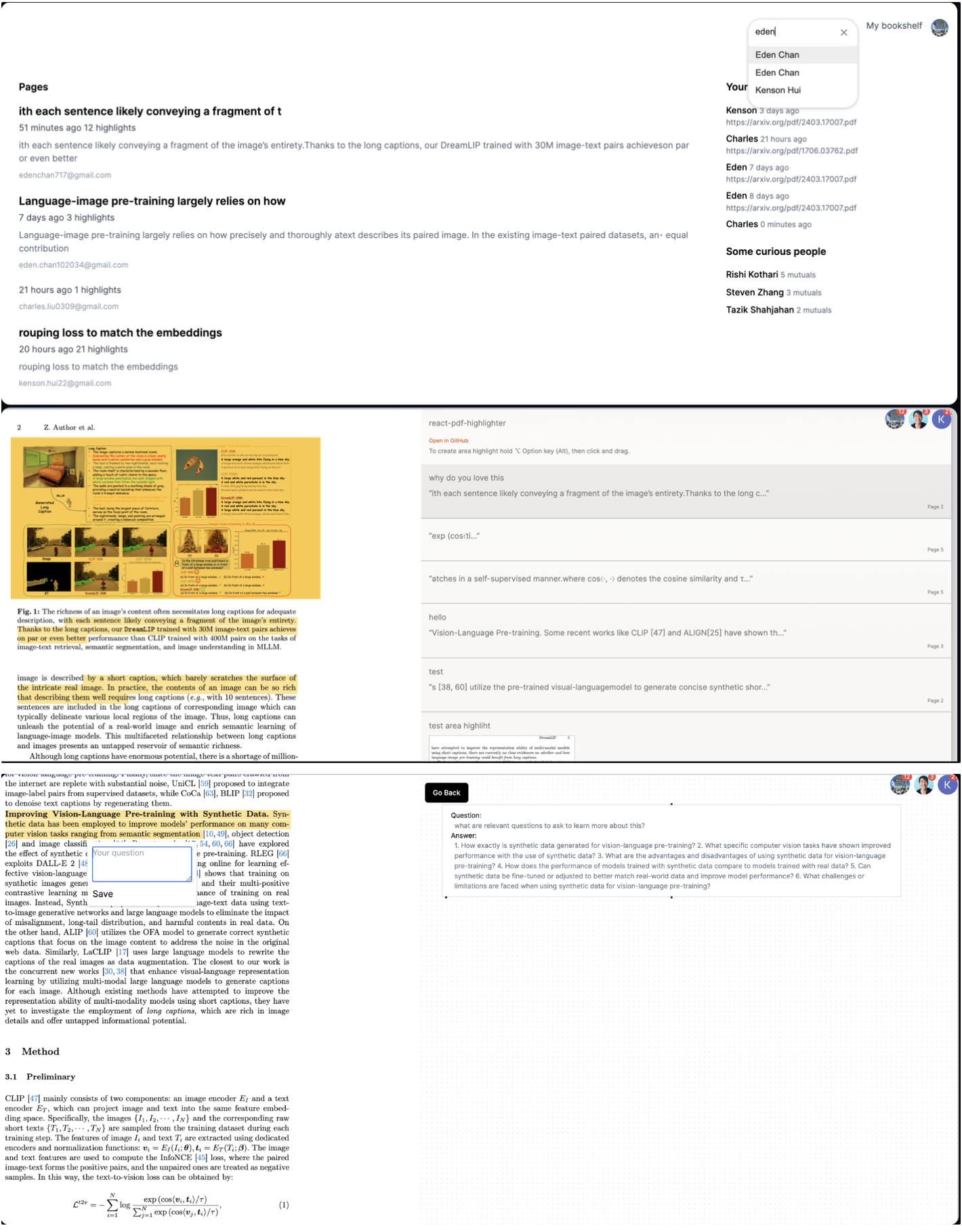
Reading papers should be interactive, and social.
It’s easy to feel lost, and get stuck learning something new and complex. it’s hard to ask good questions, when you don’t know what you want to learn. Your curiosity should be your guide for learning. But who guides your curiosity?
my/space is your trusted guide in navigating research fields and accelerating your curiosity. It’s designed to help you grok a field, and speedrun to the frontier.
Papers should cradle your curiosity, instead of tapering it out of difficulty or boredom. Papers should be a living and interactive tree that grows with your curiosity. my/space maps your cognitive landscape to a visual landscape you can share.
the lore: Charles, Kenson, and Eden work on reconstructing thoughts from EEG signals. we host paper reading sessions, and as newcomers to the field, we use ChatGPT to help us understand the nuances in AI and Bio, and help us navigate unfamiliar terms.
We found that LLMs need context that’s siloed in tables, and diagrams, and relevant papers.
We want my/space to inspire curiosity in anyone to grok any field. That means tight feedback loops to minimize time feeling stuck, and visualizing your progress as you grok a field.
We do this by:
- reduce friction in explaining image diagrams and tables; experimenting with GPT vision and other multimodal models.
- rich context LLM guided reading experience; experimenting with cyclic generation (‘walking’) to give AI models the ability to request new information, discover long-range relationships in the information and combine them for better results.
- read between the lines by seeing “expert” notes. eg. attention is all you need, they use sinusoidal functions for positional embeddings but that’s no longer done in practice.
- a source of truth mapping out your progress across all the papers you’ve read visualizing your progress in understanding a field as you grow your personal knowledge forest
A bonus is the social integration.
We drew inspiration from Cursor and Curius.
my/space is designed to be the de facto tool for paper reading groups.
We’re starting with PDFs for research papers but we think this could eventually extend this to policy documents and other context-hungry, hard to understand papers.